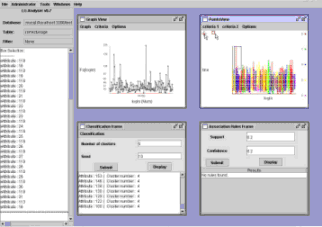
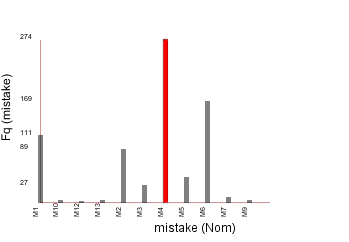
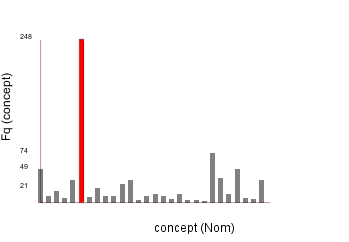
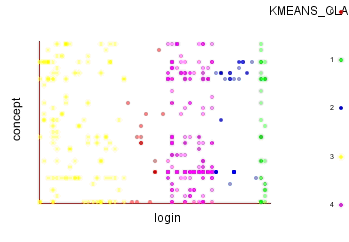
|

5. References
[1] CHIC, Logiciel d'analyse de données, www.ardm.asso.fr/CHIC.html (accessed 2003)
[2] Bisson, G., A. Bronne, M.B. Gordon, J.-F. Nicaud, & D. Renaudie. "Analyse statistique de comportements d'éléves en algébre" in Proceedings of EIAH2003 Environnements Informatiques pour l'Apprentissage Humain, Strasbourg, France: Paris: INRP (2003).
[3] Zaiane, O.R. "Web Usage Mining for a Better Web-Based Learning Environment" in Proceedings of Conference on Advanced Technology for Education (CATE'01), pp 60-64, Banff, Alberta (2001).
[4] Mazza, R. & V. Dimitrova. "CourseVis: Externalising Student Information to Facilitate Instructors in Distance Learning" in Proceedings of 11th International Conference on Artificial Intelligence in Education (AIED03), F. Verdejo and U. Hoppe (Eds), Sydney: IOS Press (2003).
[5] SPSS, Clementine, www.spss.com/clementine/ (accessed 2005)
[6] WEKA, www.cs.waikato.ac.nz/ml/weka (accessed 2003)
[7] Sweller, J., "Some cognitive processes and their consequences for the organisation and presentation of information". Australian Journal of Psychology. 45(1): p. 1-8 (1993).
[8] Agrawal, R. & R. Srikant. "Fast Algorithms for Mining Association Rules" in Proceedings of VLDB, Santiago, Chile (1994).
[9] Merceron, A. & K. Yacef. "A Web-based Tutoring Tool with Mining Facilities to Improve Learning and Teaching" in Proceedings of 11th International Conference on Artificial Intelligence in Education., F. Verdejo and U. Hoppe (Eds), pp 201-208, Sydney: IOS Press (2003).
[10] Merceron, A. & K. Yacef, "Educational Data Mining: a Case Study (paper accepted for the conference on Artificial Intelligence in Education, AIED2005)". Amsterdam, The Netherlands (2005).
[11] Beck, J., ed. Proceedings of ITS2004 workshop on Analyzing Student-Tutor Interaction Logs to Improve Educational Outcomes. Maceio, Brazil (2004).
[12] Choquet, C., V. Luengo, & K. Yacef, eds. Workshop on "Student usage analysis" to be held in conjunction with AIED 2005, Amsterdam, The Netherlands, July 2005. (2005). |
|